Following from my previous post on getting paged data from twitter, I thought it would be interesting to use ML.NET to do a little analysis. A common problem solved with machine learning is doing sentiment analysis on text to evaluate how positive or negative something is. To solve this problem with ML.NET really isn’t that much code and so its a nice entry point into their machine learning offering.
The first thing you need to do with any machine learning is to get a reasonable dataset. I got mine from Kaggle which has a lot of options if you want to spend some time to get a little closer to realistic. To be honest, because this wasn’t for production I didn’t really spend too much time selecting one. What you really need to do is to pick one that matches your use case as closely as possible. Mine rates tweets that are quite informal but for it to be effective, I need to be careful that the language of the tweets are relatively close to my real input. Spoiler: They’re most probably not.
Once you have the data, you can just load it into a dataview with your MlContext object. Whats sort of interesting is that it doesn’t actually load it when calling the function. A dataview is lazily evaluated and so it will only actually try load it when you want to use it and even then, it will load what it is working on and not the whole file at once.
var mlContext = = new MLContext(42);
IDataView dataView = mlContext.Data.LoadFromTextFile<SentimentData>(_dataPath, hasHeader: true, separatorChar: ',', allowQuoting: true, trimWhitespace: true);
This is the input and output class that I will use. ML.NET relies on attributes to map columns of data to the internal dataset.
public class SentimentData
{
[LoadColumn(1), ColumnName("Label")]
public bool Sentiment { get; set; }
[LoadColumn(2)]
public string SentimentText { get; set; }
}
public class SentimentPrediction : SentimentData
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
public float Probability { get; set; }
public float Score { get; set; }
}
I then run a test/train split on the data. This means that I will use 80% of the data to train and the other 20% to evaluate how well my model tracks the remaining data. This is quite important because you need to understand how accurate your prediction really is. For real use cases, I would also cross validate the model to make sure that my random sample for test/train split isn’t randomly more or less accurate. Luckily ML.NET also provides a function for this.
TrainTestData splitDataView = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2, seed: 0);
I then use something called a transform to Featurize the tweet text. In simple terms, this removes punctuation and stores occurrences of each word.
The Classification algorithm I used is a Binary Classification trainer because I am classifying the text into either Good or Bad. If I was classifying it into more than 2 states then I would use a Multiclass Classification trainer. Calling Fit will actually create the prediction model with the data. Depending on the size of the dataset, this might take a while!
var estimator = mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: nameof(SentimentData.SentimentText))
.Append(mlContext.BinaryClassification.Trainers.SdcaLogisticRegression(labelColumnName: "Label", featureColumnName: "Features"));
var model = estimator.Fit(trainSet);
With that model I can create a prediction engine to evaluate the sentiment of text.
var predictionFunction = mlContext.Model.CreatePredictionEngine<SentimentData, SentimentPrediction>(model);
string text = "This is bad."
SentimentPrediction result = predictionFunction.Predict(new SentimentData { SentimentText = text });
Its really not that much code to do this. I built it into my previous twitter search engine and you can get the source here. The code wraps the prediction a little but its essentially what I have shown you.
When I start up the console app I get the following output.
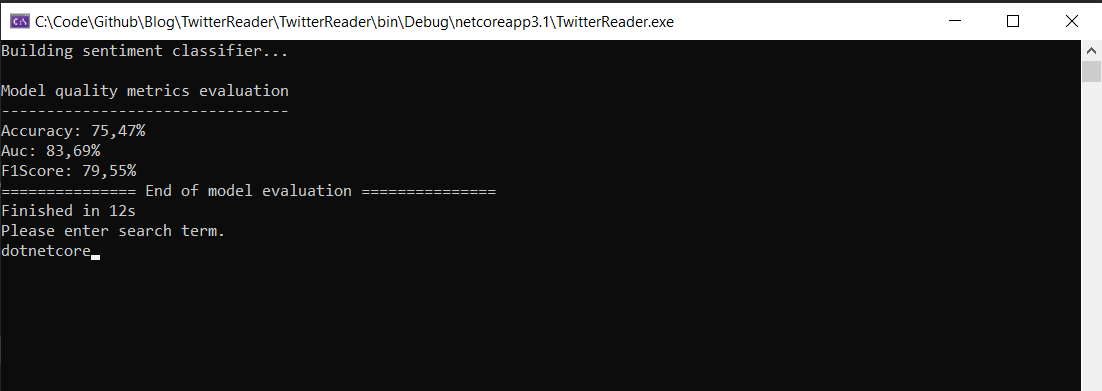
Its not something you would want to do in production but I run a evaluate on the model on startup to see how accurate the prediction is.
private void Evaluate(MLContext mlContext, ITransformer model, IDataView testSet)
{
IDataView predictions = model.Transform(testSet);
var metrics = mlContext.BinaryClassification.Evaluate(predictions, "Label");
Console.WriteLine();
Console.WriteLine("Model quality metrics evaluation");
Console.WriteLine("--------------------------------");
Console.WriteLine($"Accuracy: {metrics.Accuracy:P2}");
Console.WriteLine($"Auc: {metrics.AreaUnderRocCurve:P2}");
Console.WriteLine($"F1Score: {metrics.F1Score:P2}");
Console.WriteLine("=============== End of model evaluation ===============");
}
Its not terribly accurate even with its own training data but for my uses it does the job. To be honest, that accuracy could go down or up depending on the type of text that I feed it.
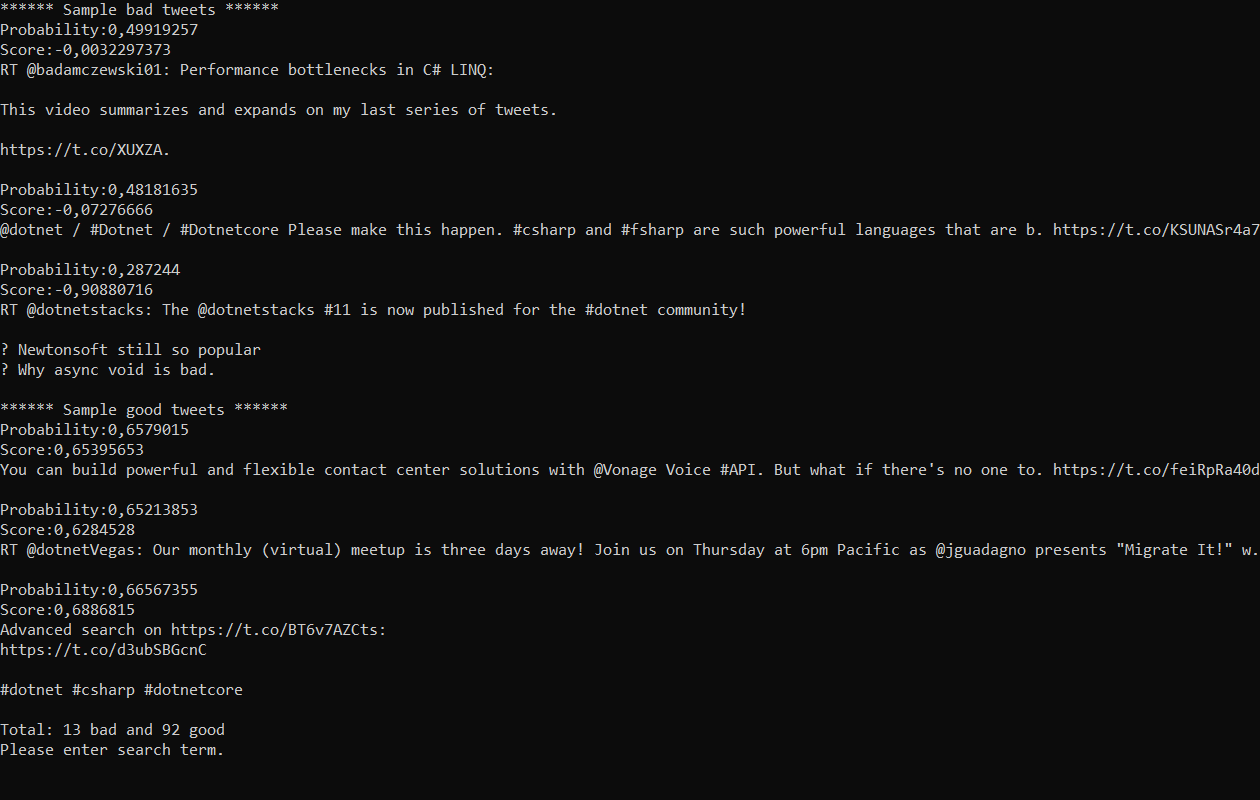
Just to finish off I did a search and you will be happy to know that there are more positive things said about dotnetcore than negative over the last day. Ship it!
Small note: ML.NET is great but it still feels a little in beta. Running this example gave strange errors on the latest stable build which forced me to the latest pre-release build with some bug fixes in. I’m sure this is just a temporary thing but worth noting if you want to start using it.